Offline RL with Hierarchical Action Chunking
Abstract
Offline goal-conditioned reinforcement learning (RL) holds the promise of learning general-purpose policies from static datasets. However, effectively scaling these methods to long-horizon tasks remains a significant challenge due to the "curse of horizon," where value estimation errors can compound through long chains of bootstrapped Bellman backups. Existing hierarchical approaches mitigate this by decomposing tasks into subgoals, yet they often rely on low-level controllers that suffer from myopic execution and biased value estimates. In this work, we propose Hierarchical Implicit Q-Chunking (HiQC), an offline RL algorithm that combines high-level latent planning with low-level action chunking. By conditioning the low-level critic on temporally extended action sequences, HiQC enables unbiased \(k\)-step value backups, effectively compressing the horizon at both the planning and execution levels. We theoretically demonstrate that this dual decomposition results in a tighter bound on value error under a bounded per-backup error model compared to standard hierarchy or flat chunking alone. Empirically, HiQC outperforms strong baselines on the OGBench suite, particularly in challenging long-horizon navigation tasks such as humanoid-giant, while maintaining robust performance on high-dimensional manipulation tasks.
Motivation: The Curse of Horizon
A major obstacle to the success of offline RL in complex environments is the curse of horizon. Popular offline RL algorithms rely on temporal difference (TD) learning, which minimizes the error between a value estimate and a bootstrapped Bellman target. As the task horizon increases, extrapolation errors on out-of-distribution actions accumulate through long chains of recursive Bellman backups, rendering value estimates highly unreliable for distant goals.
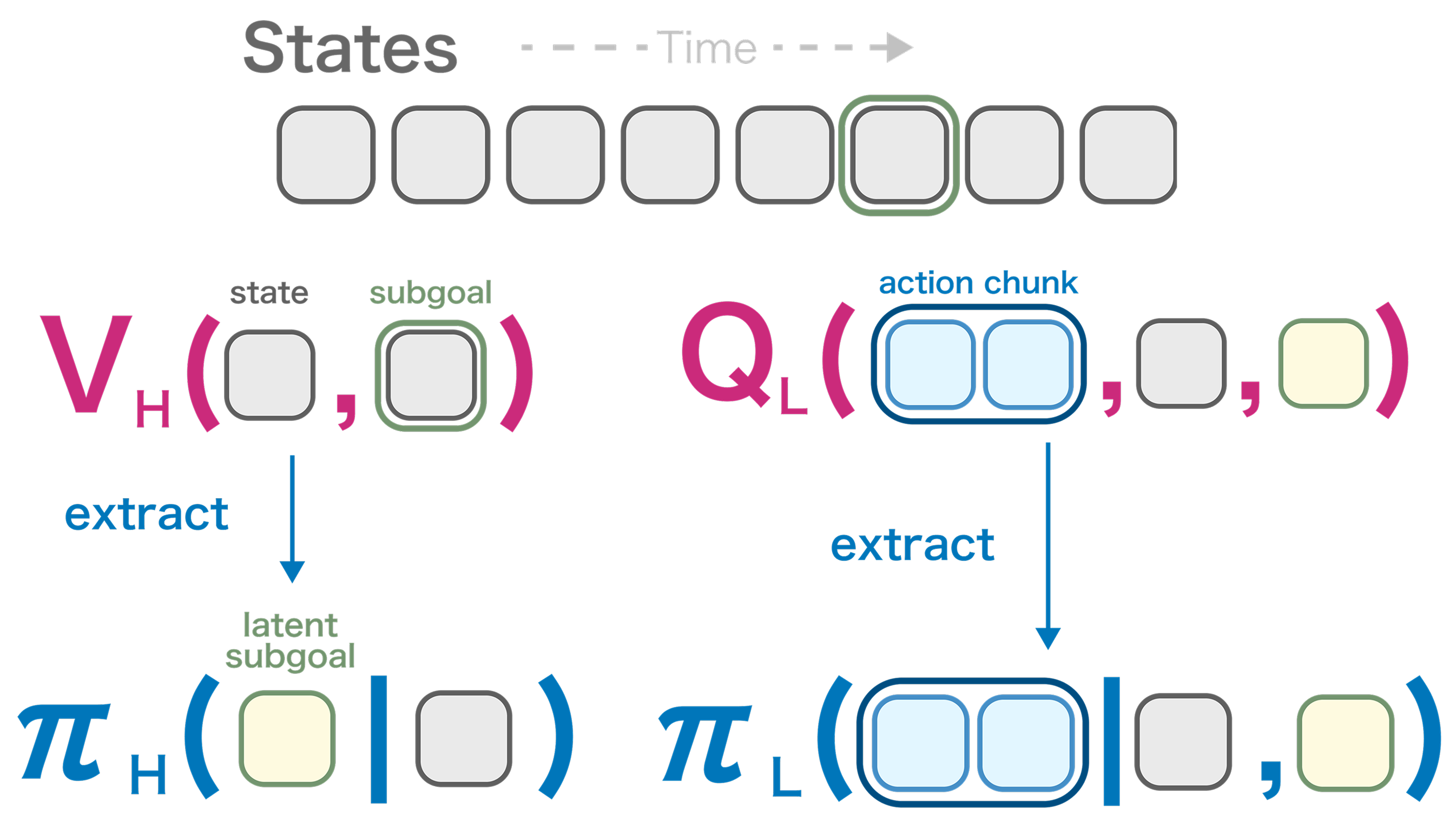
Methodology: Hierarchical Implicit Q-Chunking
HiQC introduces an offline RL algorithm designed to mitigate error accumulation through a dual horizon reduction on both the planning horizon and the execution horizon:
- High-Level (Planning Horizon \(c\)): Learns a latent planner using Implicit V-Learning. It decomposes the global task into intermediate latent subgoals \(z\) to bridge distant states.
- Low-Level (Execution Horizon \(k\)): Executes \(k\)-step action chunks \(\mathbf{a}\) to reach \(z\). The policy is parameterized via Conditional Flow Matching (CFM) to model complex, multi-modal action distributions.
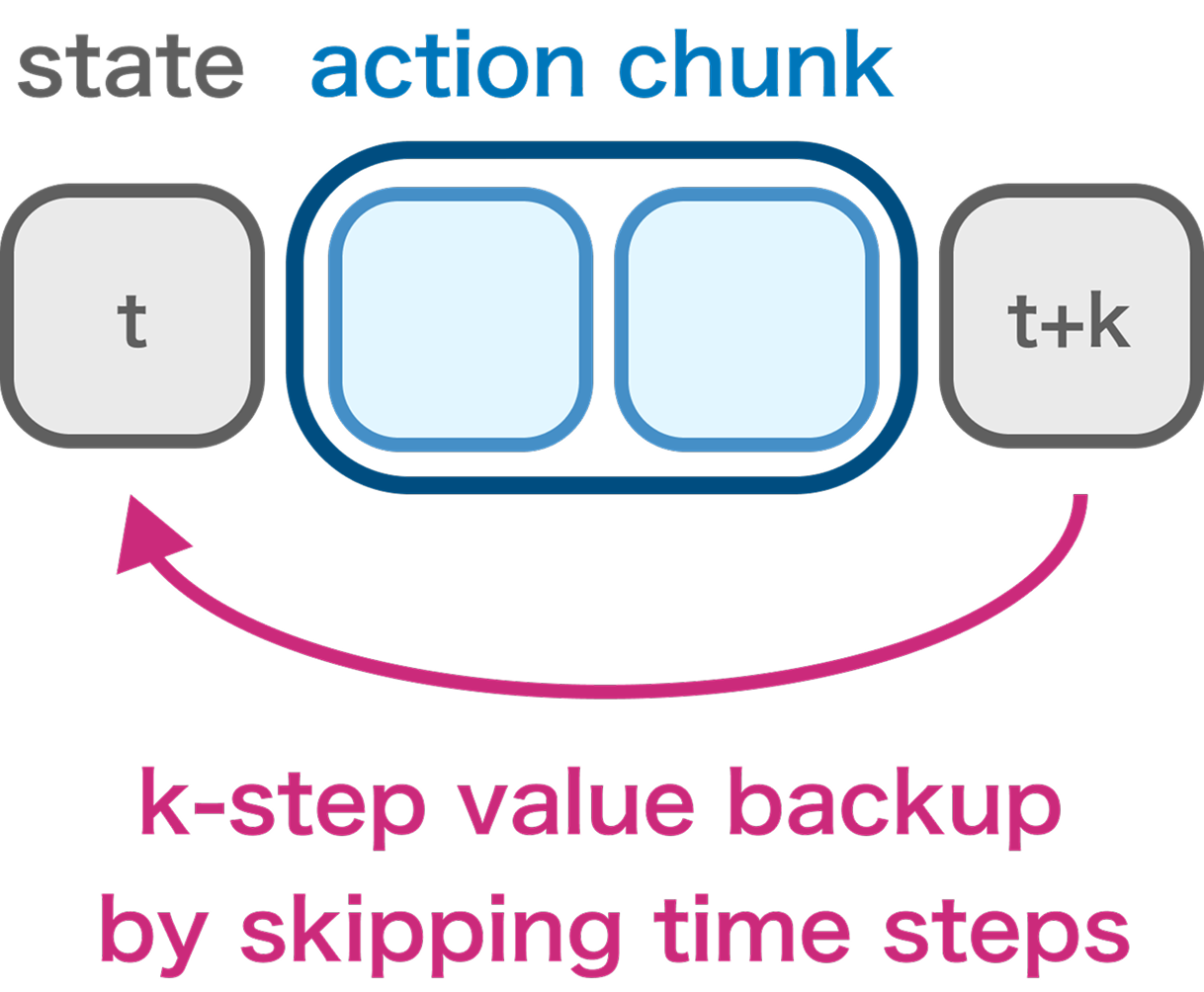
- Chunked Critic (Unbiased Backups): By conditioning the Q-function on the full action sequence \(\mathbf{a}\) present in the dataset, HiQC allows the low-level critic to perform unbiased \(k\)-step backups without suffering from off-policy bias.
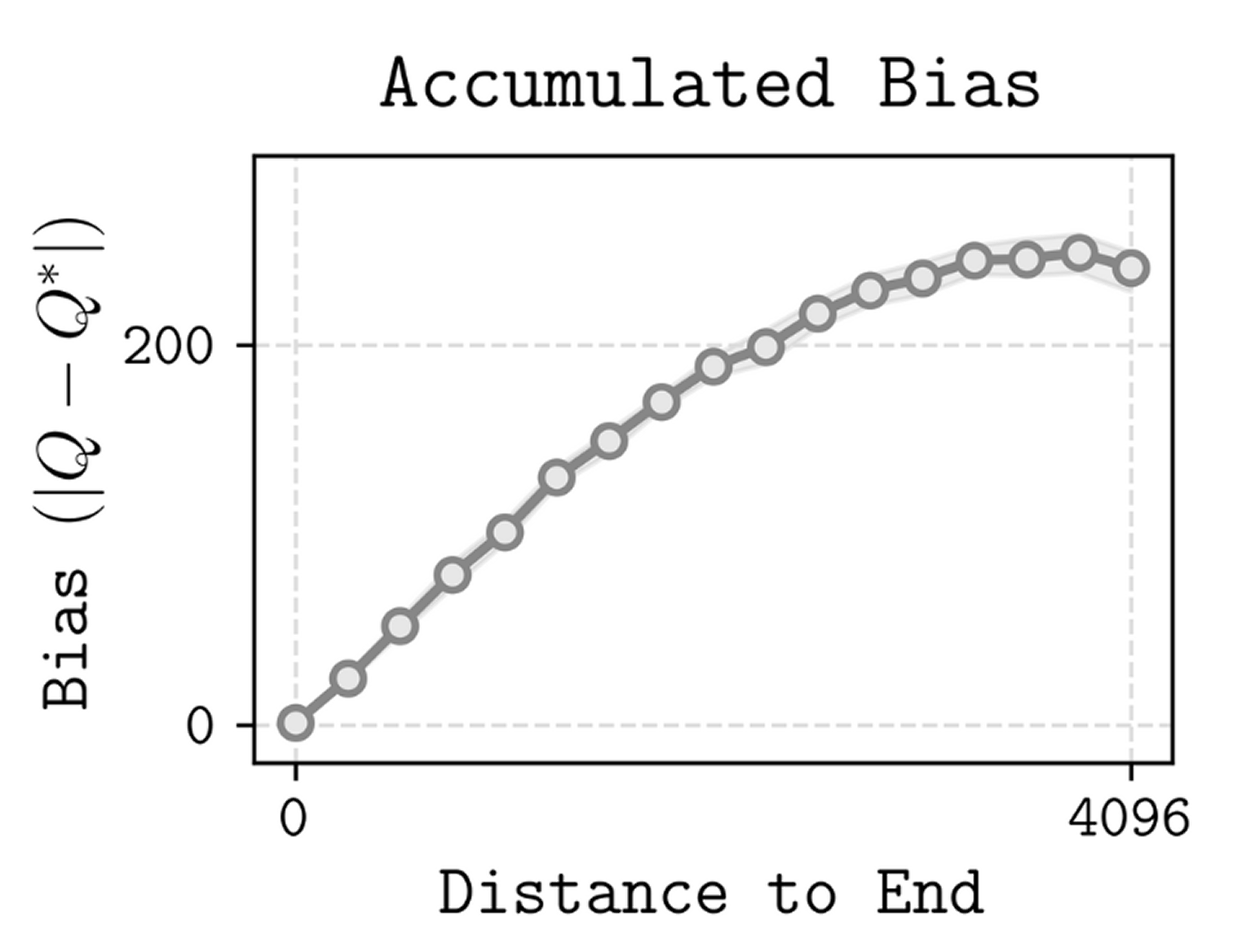
Theoretical Analysis
Under a bounded per-backup error model, we analyze how value learning propagates information backward. Each bootstrap step introduces bounded error \(\epsilon\), meaning the total error grows linearly with the bootstrap depth (the number of backups required to propagate a terminal signal to the start state).
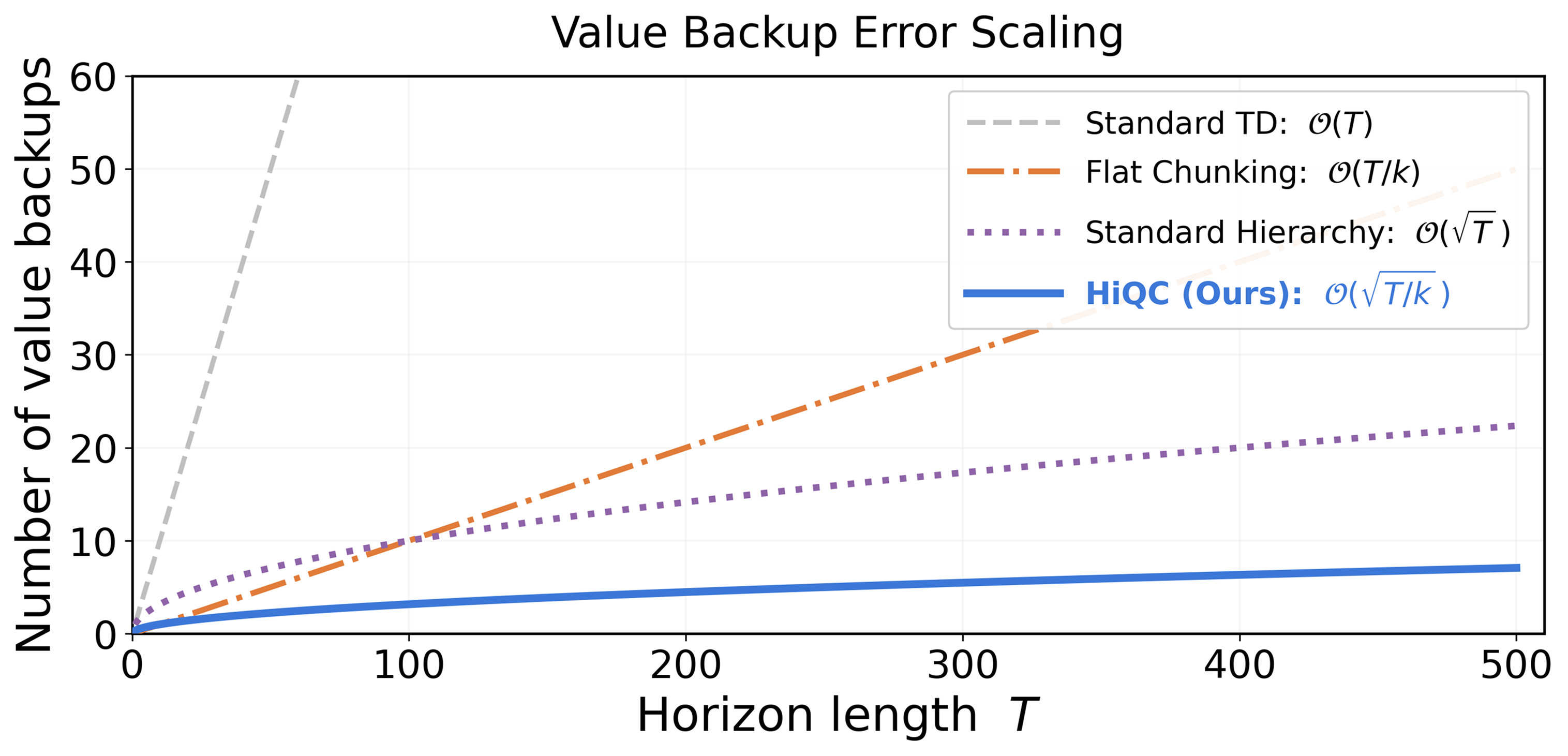
Decomposing a task horizon \(T\) into subgoals spaced by \(c\) steps and action chunks of size \(k\), HiQC drastically reduces the required recursion depth. We prove that HiQC yields a strictly tighter error bound and improved scaling compared to baselines:
- Standard TD Learning: \(\mathcal{O}(T)\)
- Flat Action Chunking: \(\mathcal{O}(T/k)\)
- Standard Hierarchy: \(\mathcal{O}(\sqrt{T})\)
- HiQC (Ours): \(\mathcal{O}(\sqrt{T/k})\)
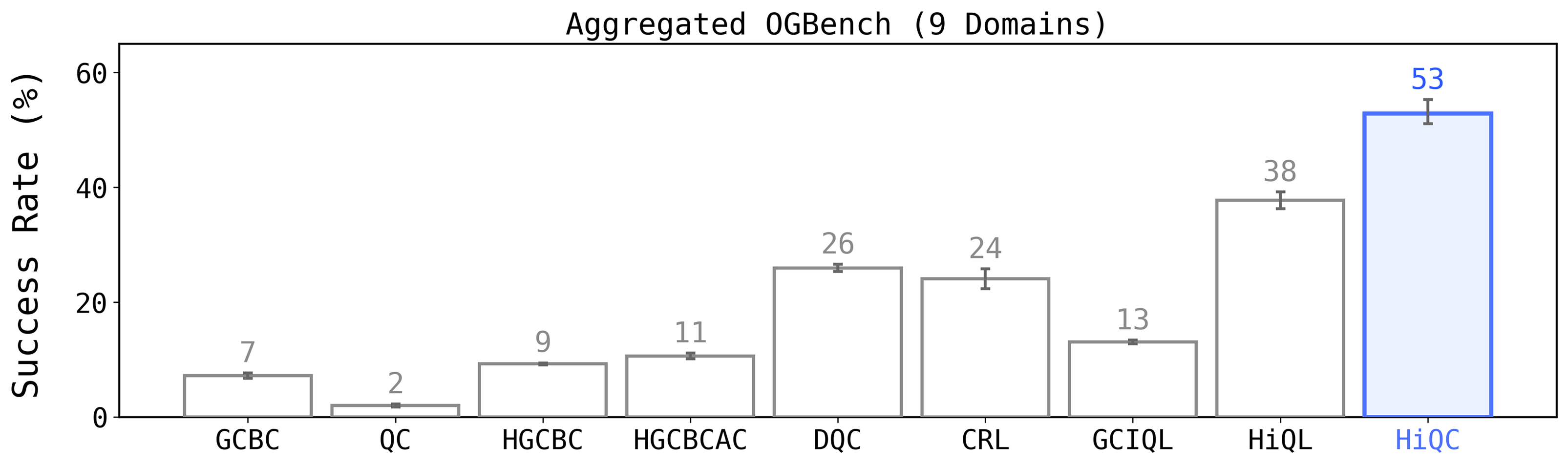
Results on OGBench
We extensively evaluate HiQC on the OGBench suite, specifically stress-testing across 9 domains encompassing both locomotion (antmaze, humanoidmaze) and manipulation (cube, scene, puzzle).

HiQC outperforms standard hierarchical (HIQL) and flat chunking (DQC/QC) baselines. The performance gap is most pronounced in extremely long-horizon navigation tasks like humanoidmaze-giant, where flat methods fail completely due to the curse of horizon.
Citation
If you find this work useful, please consider citing our paper:
@inproceedings{
jawaid2026offline,
title={Offline {RL} with Hierarchical Action Chunking},
author={Ahad Jawaid},
booktitle={Workshop on Latent {\&} Implicit Thinking {\textendash} Going Beyond CoT Reasoning},
year={2026},
url={https://openreview.net/forum?id=ITL0pDyVF8}
}